1.简介
Text Generation Inference(TGI)是 HuggingFace 推出的一个项目,作为支持 HuggingFace Inference API 和 Hugging Chat 上的LLM 推理的工具,旨在支持大型语言模型的优化推理。
2.主要特性
- 支持张量并行推理
- 支持传入请求 Continuous batching 以提高总吞吐量
- 使用 flash-attention 和 Paged Attention 在主流的模型架构上优化用于推理的 transformers 代码。注意:并非所有模型都内置了对这些优化的支持。
- 使用bitsandbytes(LLM.int8())和GPT-Q进行量化
- 内置服务评估,可以监控服务器负载并深入了解其性能
- 轻松运行自己的模型或使用任何 HuggingFace 仓库的模型
- 自定义提示生成:通过提供自定义提示来指导模型的输出,轻松生成文本
- 使用 Open Telemetry,Prometheus 指标进行分布式跟踪
3.支持的模型
4.适用场景
依赖 HuggingFace 模型,并且不需要为核心模型增加多个adapter的场景。
5.项目架构
整个项目由三部分组成:
- launcher
- router
- serve
Launcher、Router和Server(Python gRPC服务)都是服务的组成部分,它们各自承担不同的职责,共同提供一个完整的文本生成推理服务。以下是它们之间的关系:
- Launcher:这是服务的启动器,它负责启动和运行服务。它可能会启动 Router,并设置好所有的路由规则。然后,它会监听指定的地址和端口,等待并处理来自客户端的连接。当接收到一个连接时,它会将连接转发给Router 进行处理。
- Router:这是服务的中间件,它的主要职责是路由和调度请求。当客户端发送一个请求时,Router 会接收这个请求,然后根据请求的内容和当前的系统状态,决定将请求路由到哪个处理器进行处理。这个处理器可能是Server 中的一个 gRPC 方法。Router 的目的是有效地管理和调度系统资源,提高系统的并发处理能力和响应速度。
- Server(Python gRPC服务):这是服务的核心部分,它实现了文本生成推理的主要逻辑。它提供了一些 gRPC 方法,如 Info、Health、ServiceDiscovery、ClearCache、FilterBatch、Prefill 和 Decode,这些方法用于处理客户端的请求,执行文本生成的推理任务,并返回结果。这个服务可能运行在一个单独的服务器上,独立于Launcher 和 Router。
5.1 launcher 启动器
顾名思义,launcher 启动器,就是负责启动的程序,主要做以下工作:(在 launcher/src/main.rs 中)
- 通过 serve 的命令下载模型,代码中执行的函数为:
download_convert_model(&args, running.clone())?; - 启动 serve ,代码中执行的函数为:
spawn_shards(...) - 启动 router,代码中执行的函数为:
spawn_webserver(args, shutdown.clone(), &shutdown_receiver)?;
所以,router 和 serve 负责主要的逻辑处理与模型调用。在项目中有一个架构图,可以更加直观的认识到它们之间的关系,其架构如下图所示:
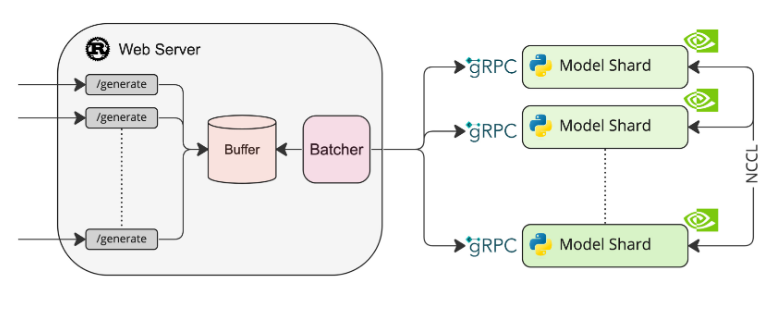
5.2 router 路由
可以看到 router 这个 webserver 负责接收请求,然后放在 buffer 中,等收集到一定量的数据后,一个 batch 一个 batch 的以 rpc 的方式发送给 serve 的去处理。
对外暴露的 url 很少同时也很精简,只有四个:
/generate: 一次性生成所有回答的 token/generate_stream:流式的生成所回答的 token (就类似于 chatgpt 一样,一个字一个字的显现)/metrics: 获取该服务的metrics信息。/info:获取模型的相关信息
5.3 serve
在图中,也可以看到,在每个卡上都启动了一个 serve,被叫做 shard,这也是 launcher 的作用之一,通过参数来决定 serve 启动的情况。
在 serve 端的代码,有两个命令行启动脚本(
serve/text_generation_server/cli.py):# 下载模型权重的方法 @app.command() def download_weights( ... ) ... # 启动 serve 服务的方法 @app.command() def serve( ... ) ...
其实内部逻辑也很简单,稍微处理一下数据后,直接调用 model 的接口来处理。
Server 对外暴露了一下接口:(这里说的对外,指的是 router )- Info : 返回 model 信息
- Health : 检查 serve 的健康状况
- ServiceDiscovery : 服务发现,实现也很简单,将所有的 serve 的地址发送出去
- ClearCache : 清除 cache 中的数据 (cache 的功能再看)
- FilterBatch
- Prefill
- Decode
cache 中的存储单位是 batch (在 router 中提过,router 就是一个 batch 一个 batch 来传的。)
5.4 内部接口的含义
再然后,就剩下最重要的三个功能:FilterBatch、Prefill、Decode
FilterBatch 流程如下:(使用场景还不太清楚)
先从 cache 中以 batch_id 获取特定的 batch 再从 batch 中过滤出我们想要留下的 request_ids(这里的 request_id 指的是 客户端发送的请求 id ) 过滤后,再将 batch 放回 cache 中。
Prefill 的主要功能是:
- 从 router 接收 batch ,然后根据模型给的
from_pb方法整理一下 batch 中的信息 并且 通过tokenizer来将相应的词转化成词向量。(from_pb 方法之后在说) - 将 整理后的 batch 信息,通过 model 的 generate_token 方法,生成新的 token (也就是预测的词),同时也会返回 next_batch。(generate_token 方法之后在说)
- 将 next_batch 存放到 cache 中。
- 返回消息。
Decode 的功能也很简单,主要功能是:
- 通过 request 传入的 batch.id 从 cache 中获取 batch
- 将这些 batch 通过 model 的 generate_token 方法,生成新的 token,同时会返回 next_batch。
- 将 next_batch 存放到 cache 中。
- 返回消息。
主要是第一步,从 缓存中获取 batch,这样有两个好处:第一,request 不需要传输历史的 信息,上下文都在 cache 中;第二,cache 中缓存的是 词向量 的信息,所以,在每次预测词的时候,只需要将传入的 信息 通过词嵌入 转化成 词向量,其他的信息就不需要再做转化了,减少了大量的计算工作。
参考资料: