1.Model-free RL
Both of the policy iteration and value iteration assume the direct access to the dynamics and rewards of the environment. But, in a lot of real-world problems, MDP model is either unknown or known by too big or too complex to use.
Model-free RL can solve the problems through interaction with the environment
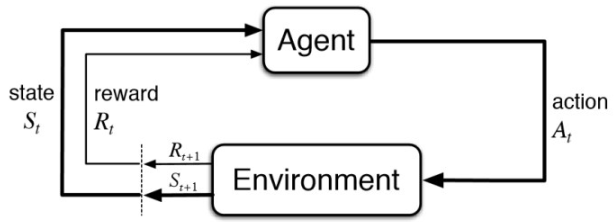
No more direct access to known transition dynamics and reward function
Tarjectories / episodes are collected by the agent's interaction with the environment
Each trajectory / episode contains
2.Model-free prediction
policy evaluation with access to the model
Estimating the expected return of a particular policy if we don't have access to the MDP models:
- Monte Carlo policy evaluation
- Temporal Difference (TD) learning
3.Monte Carlo Policy Evaluation
3.1 Overall
蒙特卡洛的方法主要是基于采样的方法,让agent与环境进行交互,得到很多轨迹。每一个轨迹都会得到一个实际的收益。然后直接从实际的收益来估计每个状态的价值
Return : under policy
, thus expectation over trajectories generated by following
MC simulation : we can simply sample a lot of trajectories, compute the actual returns for all the trajectories, then average them
MC policy evaluation uses empirical mean return instead of expected return
MC does not require MDP dynamics / reward, no bootstrapping, and does not assume state is Markov
Only applied to episodic MDPs(each episode terminates)
3.2 Alg
当要估计某个状态的时候,从这个状态开始通过数数的办法,数这个状态被访问了多少次,从这个状态开始我们总共得到了多少的return,最后再取empirical mean,就会得到每个状态的价值。
To evaluate state V(s)
- Every time-step that state is vistied in an episode
- Increment counter
- Increment total return
- Value is estimated by mean return
By law of large numbers(大数定律), as
3.3 Incremental Mean
写成逐步叠加的办法。
Mean from the average of samples
通过采样很多次,就可以平均;然后进行分解,把加和分解成最新的的值和最开始到的值;然后把上一个时刻的平均值也带入进去,分解成乘以上一个时刻的平均值;这样就可以把上一个时刻的平均值和这一个时刻的平均值建立一个联系。
通过这种方法,当得到一个新的的时候,和上一个平均值进行相减,把这个差值作为一个残差乘以一个learning rate,加到当前的平均值就会更新我们的现在的值。这样就可以把上一时刻的值和这一时刻更新的值建立一个联系。
3.4 Incremental MC Updates
把蒙特卡洛方法也写成Incremental MC更新的方法。
Collect one episode
For each state with computed return
Or use a running mean (old episodes are forgotten). Good for non-stationary problems
3.5 Difference between DP and MC for policy evaluation
Dynamic Programming (DP) computes by bootstrapping the rest of the expected return by the value estimate
Iteration on Bellman expectation backup:
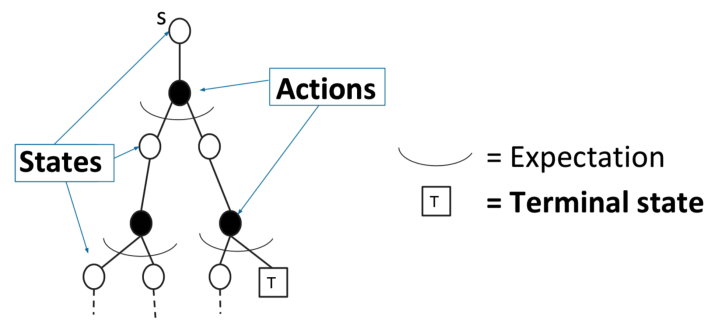
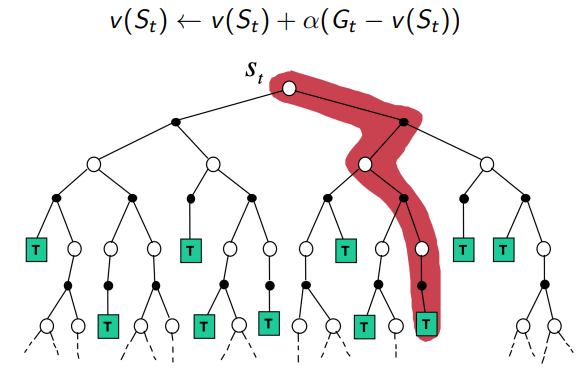
MC updates the empirical mean return with one sampled episode
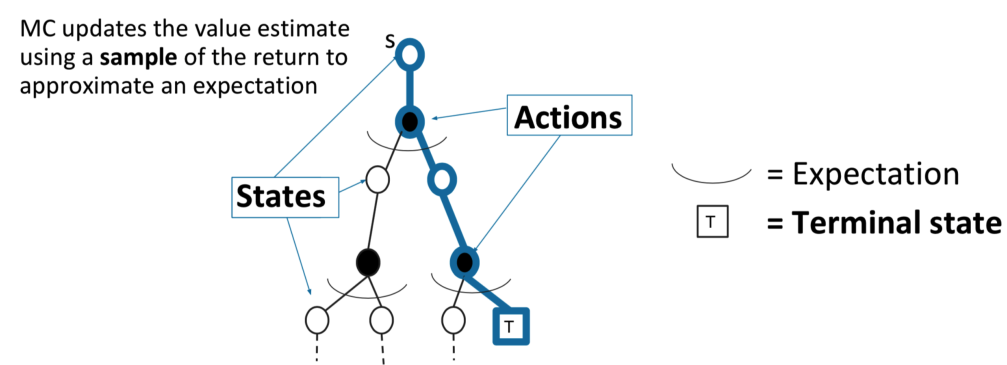
3.6 MC相对于DP的优点
- MC可应用于环境未知(transition function)
- 对于环境比较复杂的情况,转移概率很难计算,MC基于采样,不需要计算。
- 计算量的优势:DP要考虑所有的状态转移情况才能更新一步。MC在估计单个状态时与总价值无关。效率更高。
4.Temporal-Difference (TD) Learning
TD是DP和MC折中的一种办法,利用bootstrapping可以从不完整的episode学习。也是基于采样的可用于unknown MDP(transition/rewards)环境中
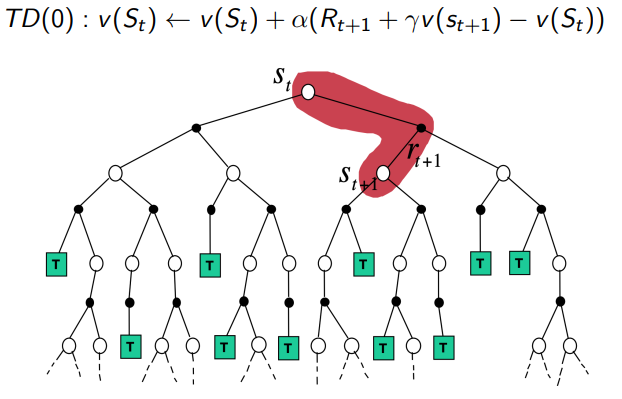
4.1 Alg : TD(0)
TD(0)指往前看一步。
Objective: learn online from experience under policy
Simplest TD algorithm : TD(0)
Update toward estimated return
is called TD target
is called the TD error
Comparison : Incremental Monte-Carlo
Update toward actual return given an episode
4.2 Advantages of TD over MC
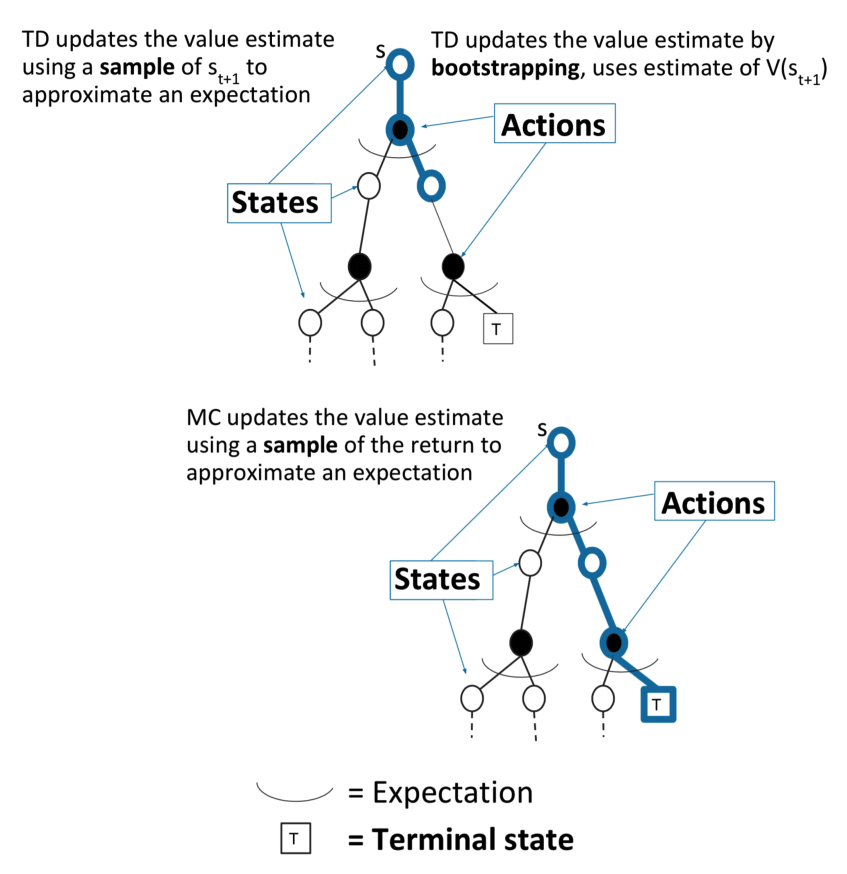
- TD每经过一个timestep都可以更新;MC要等一个episode结束后才能更新。
- TD可以从不完整的序列学习,MC要用完整的序列才能学习。
- TD可以用在没有终止状态的环境中,MC不可以。
- TD利用的MDP的特征(当前状态和之前的状态没有关系),MC并没有利用,它采样并利用了整个轨迹。使得MC在non-Markov环境下更有效。
4.3 n-step TD
n-step TD methods that generalize both one-step TD and MC
We can shift from one to the other smoothly as needed to meet the demands of a particular task.
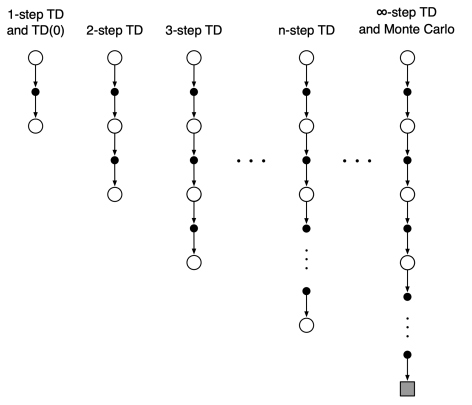
4.4 n-step TD prediction
Consider the following n-step returns for
Thus the n-step return is defined as
n-step TD
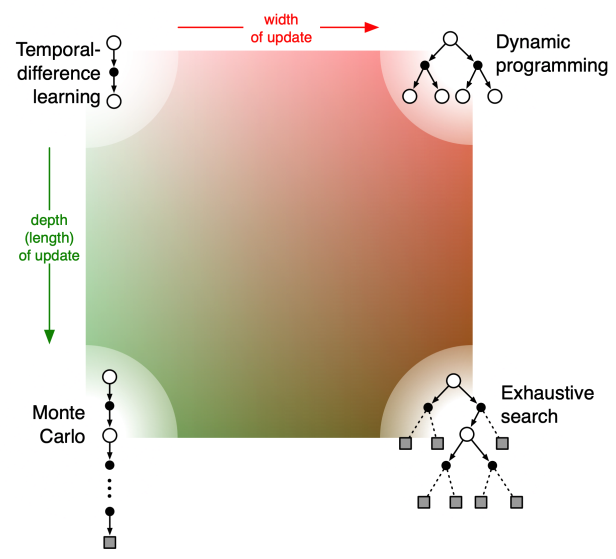
4.5 Bootstrapping and Sampling for DP, MC, and TD
Bootstrapping: update involves an estimate
- MC does not bootstrap
- DP bootstraps
- TD bootstraps
Sampling: update samples an expectation
- MC samples
- DP does not sample
- TD sample
Dynamic Programming Backup
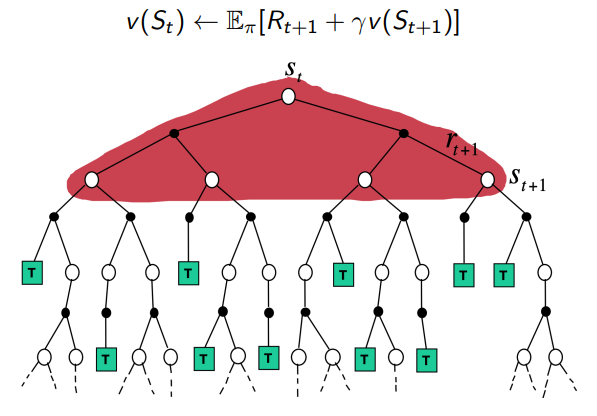
Monte-Carlo Backup
Temporal-Difference Backup
Unified View of Reinforcement Learning
5.Model-free Control for MDP
Model-free Control : Optimize the value function of an unknow MDP
Generalized Policy Iteration (GPI) with MC and TD
5.1 Policy Iteration
- Evaluate the policy (computing v given current )
- Improve the policy by acting greedily with respect to
Compute the state-action value of a policy \pi :
在不知道R和P的情况下,如果获得R(s,a)和P(s'|s,a)并作出决策呢?
5.2 基于MC的广义Policy Iteration
用蒙特卡罗MC的方法取代DP的方法去估计V/Q函数。
用方法去改进policy improvement获得。
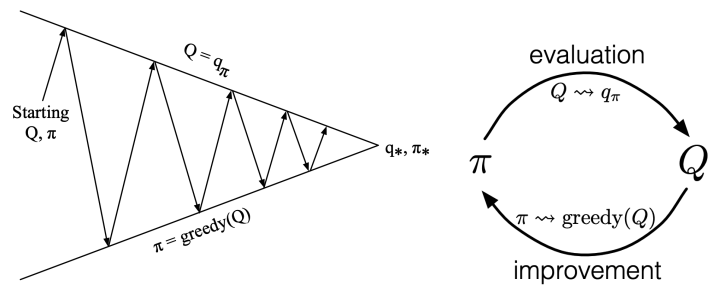

(1)Policy Evalution
原来的policy evalution :
现在MC的 Policy evalution

(2)Policy Improvement
考虑 exploration 和 exploitation 的 tradeoff 的问题。
Trade-off between exploration and exploitation (we will talk about this in later lecture)
Exploration : Ensuring continual exploration
- All actions are tried with non-zero probability
- With probability choose the greedy action
- With probability choose an action at random
5.3 基于TD的广义Policy Iteration
(1)MC vs TD
TD相比MC的优势:方差小、在线的、处理不完整的序列
用TD的方法可以取代DP/MC的方法去估计V函数。同样用方法去改进policy improvement获得。那如何使用TD的方法获得呢?
(2)On-Policy 和 Off-Policy 的对比
On-Policy:学习过程中只利用我们现在正在学的这个策略,采集轨迹数据和优化策略始终都是用这个策略。
Off-Policy:保留两个策略,一个是我们要优化的目标策略 target ,另一个是探索的策略 action 。探索的策略就可以更激进,并通过 来采集数据,采到的数据给 去学习。
Off-Policy benefits:
- Learn about optimal policy while following exploratory policy
- Learn from observing humans or other agents
- Re-use experience generated from old policies
(3)On-Policy TD control:Sarsa
(S A R S A 进行循环的意思)
An episode consists of an alternating sequence of states and state-action pairs:
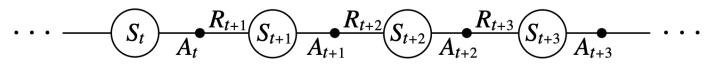
policy for one step, then bootstrap the action value function:
The update is done after every transition from a nonterminal state
TD target
Sarsa algorithm

(4)n-step Sarsa
Consider the following n-step returns for
Thus the n-step return is defined as
n-step TD
(5)Off-Policy TD control:Q-learning
We allow both behavior and target policies to improve
The target policy is greedy on
The behavior policy could be totally random, but we let it improve。
following on
Thus Q-learning target:
Thus the Q-Learning update
Q-learning algorithm

(6)Sarsa和Q-learning的区别
1. Sarsa是只利用一个策略π,而Q-Learning有两个策略π和μ
Sarsa : On-Policy TD control
Choose action from using policy derived from with Take action , observe and Choose action from using policy derived from with
Q-Learning: Off-Policy TD control
Choose action from using policy derived from with Take action , observe and Then ‘imagine’as arg max in the update target
2. backup diagram过程不同
Backup diagram for Sarsa and Q-learning
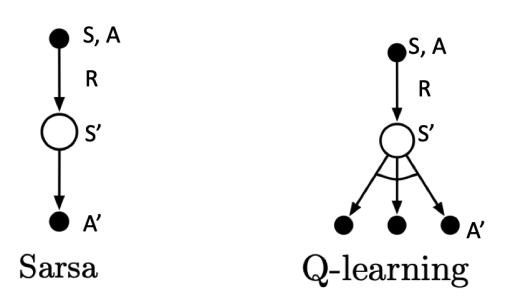
In Sarsa, and are sampled from the same policy so it is on-policy
In Q Learning, and are from different policies, with being more exploratory and determined directly by the max operator
3.Sarsa更保守,Q-Learning更激进冒险
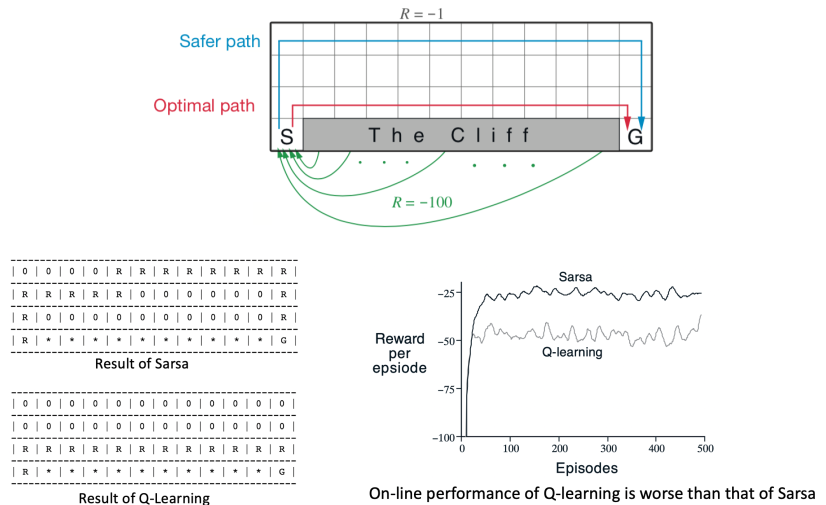
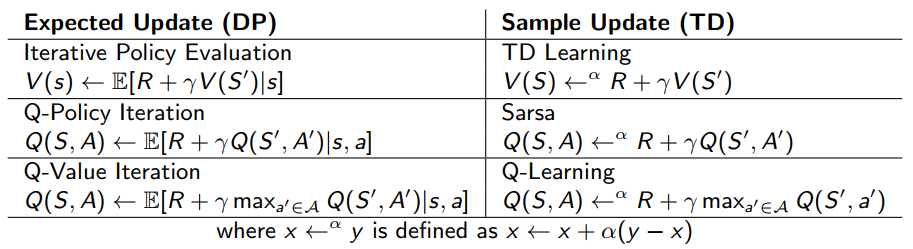
5.4 DP vs TD