Prefix Tuning / P-Tuning v2¶
1.Prefix Tuning简述¶
Prefix Tuning(论文:Prefix-Tuning:Optimizing Continuous Prompts for Generation),在输入token之前构造一段任务相关的virtual tokens作为Prefix;然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
针对不同的模型结构,需要构造不同的 Prefix。
- 针对自回归架构模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 - 针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
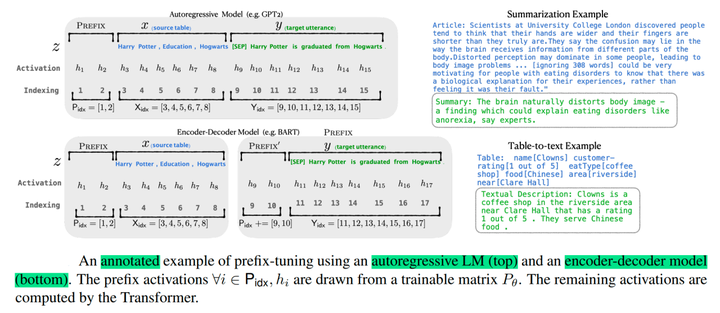
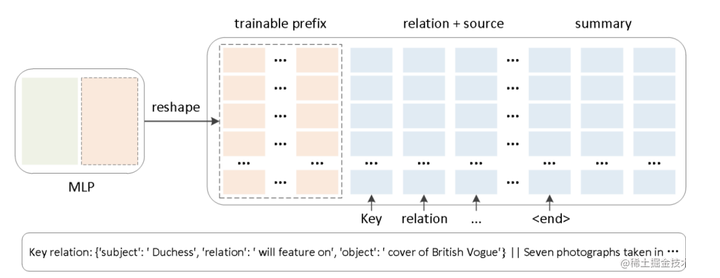
同时,为了防止直接更新 Prefix 的参数导致训练不稳定和性能下降的情况,在 Prefix 层前面加了 MLP 结构,训练完成后,只保留 Prefix 的参数。
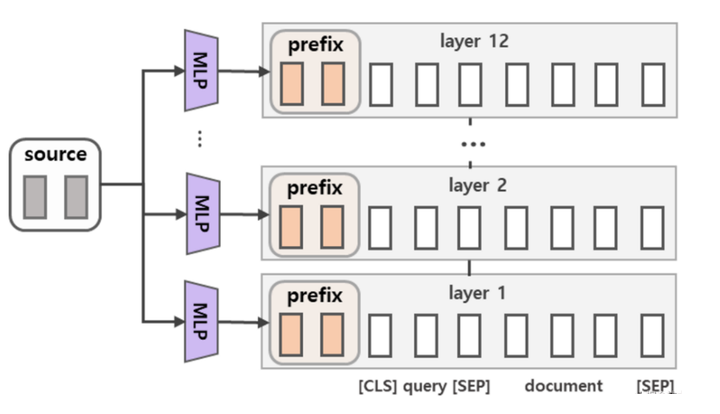
除此之外,通过消融实验证实,只调整embedding层的表现力不够,将导致性能显著下降,因此,在每层都加了prompt的参数,改动较大。
2.P-Tuning v2 简述¶
P-Tuning v2(论文: P-Tuning v2:Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks),该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%);同时,也足够参数高效。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
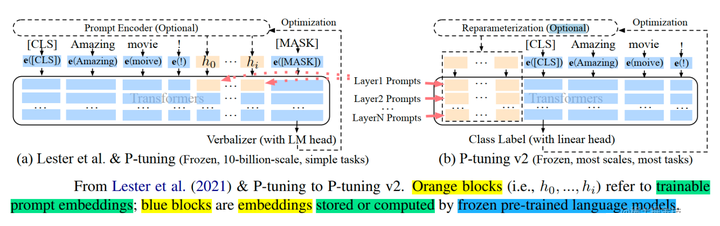
具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中,然后做了一些改进:
- 移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning 中的 MLP 、P-Tuning 中的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
- 针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与 Prefix-Tuning 中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
- 引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
- 回归传统的分类标签范式,而不是映射器。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的,它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
3.微调实践¶
3.1 引入库¶
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, PrefixTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
3.2 创建 Prefix Tuning / P-Tuning V2 微调方法对应的配置。¶
device = "cuda"
model_name_or_path = "/data/nfs/llm/model/bloomz-560m"
tokenizer_name_or_path = "/data/nfs/llm/model/bloomz-560m"
peft_config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=30,
prefix_projection=True
)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace("/", "_")
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 10
batch_size = 8
/home/guodong.li/virtual-venv/peft-venv-py310-cu117/lib/python3.10/site-packages/tqdm/auto.py:21:TqdmWarning:IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
[2023-07-21 15:07:09,626] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)
PrefixTuningConfig 配置类参数说明:
task_type:指定任务类型。如:条件生成任务(SEQ_2_SEQ_LM),因果语言建模(CAUSAL_LM)等。num_virtual_tokens:虚拟token的数量,换句话说就是提示(prompt)。inference_mode:是否在推理模式下使用Peft模型。prefix_projection:是否投影前缀嵌入(token),默认值为false,表示使用P-Tuning v2, 如果为true,则表示使用 Prefix Tuning。
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
# dataset = load_dataset("/home/guodong.li/data/peft/raft/raft.py", dataset_name, cache_dir="/home/guodong.li/data/peft/data")
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
Found cached dataset raft (/home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84) 100%|██████████| 2/2 [00:00<00:00, 414.07it/s] Loading cached processed dataset at /home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84/cache-0e20fff6b1d898ca.arrow Loading cached processed dataset at /home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84/cache-8d14a62b8a688c19.arrow
['Unlabeled', 'complaint', 'no complaint']
DatasetDict({
train:Dataset({
features:['Tweet text', 'ID', 'Label', 'text_label'],
num_rows:50
})
test:Dataset({
features:['Tweet text', 'ID', 'Label', 'text_label'],
num_rows:3399
})
})
{'Tweet text':'@HMRCcustomers No this is my first job',
'ID':0,
'Label':2,
'text_label':'no complaint'}
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print("target_max_length:", target_max_length)
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} :{x} Label :" for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["train"]
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
target_max_length:3
def test_preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} :{x} Label :" for x in examples[text_column]]
model_inputs = tokenizer(inputs)
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (max_length - len(sample_input_ids)) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs["attention_mask"][i]
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
return model_inputs
test_dataset = dataset["test"].map(
test_preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
next(iter(test_dataloader))
{'input_ids':tensor([[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 74757, 64626, 12384, 44639, 613,
52282, 2670, 79920, 3344, 1002, 368, 17646, 14472, 8348,
664, 718, 4, 19036, 17, 31849, 17, 6312, 76,
44, 62470, 56, 91, 50, 14839, 21, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 227985, 5484, 915, 405, 187059,
2256, 664, 2550, 18833, 18607, 162467, 4, 1387, 6199,
3291, 23405, 613, 4657, 17082, 566, 3432, 368, 78851,
1185, 61273, 23181, 1553, 15596, 212, 116057, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 39762, 2566, 22253, 6201, 75701, 15, 632, 718,
5840, 10006, 6201, 18881, 427, 3804, 19528, 267, 158974,
1320, 368, 10029, 632, 49666, 92, 34, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 227985, 5484, 915, 2566, 104565, 8695, 2089, 6140,
109676, 99579, 1369, 512, 368, 4570, 54, 632, 368,
1503, 241485, 132226, 15, 982, 727, 1152, 18100, 861,
32596, 77597, 168154, 1306, 132226, 4346, 87843, 17, 130462,
364, 32923, 89, 53, 8309, 20, 75, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 227985, 5484, 915, 2566,
14173, 2960, 29906, 387, 20706, 49337, 1369, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 227985, 5484, 915, 2566, 219553, 45736,
36876, 1713, 72, 707, 187205, 13002, 177324, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 233938, 28518, 13716,
427, 28146, 1119, 17918, 17, 236706, 368, 214997, 7555,
48659, 5276, 21600, 343, 17, 51416, 22403, 318, 1531,
1306, 1130, 20934, 567, 101161, 184849, 87843, 17, 1594,
15231, 2052, 16642, 20, 7180, 80, 26, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 80, 2068, 479, 2566, 80,
1376, 878, 147587, 3904, 632, 368, 6084, 65673, 78851,
11736, 15527, 19082, 33151, 461, 17, 45575, 17887, 632,
5219, 14216, 68870, 5967, 1841, 4346, 87843, 17, 1594,
14512, 27, 71, 8184, 19, 290, 63748, 77658, 915,
210]]),
'attention_mask':tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
next(iter(train_dataloader))
{'input_ids':tensor([[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 2566, 61, 31311, 6640, 1935, 15527, 3784, 46823,
664, 267, 57502, 427, 2670, 148307, 530, 524, 23099,
613, 15226, 5840, 34, 77658, 915, 210, 16449, 5952,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 46, 30579, 46,
12592, 57, 473, 3370, 199020, 267, 46019, 21302, 15804,
361, 13300, 132548, 27761, 77658, 915, 210, 1936, 106863,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 227985, 5484, 915, 2566, 47959, 6745,
19624, 13929, 2152, 722, 11045, 635, 3869, 290, 32107,
75, 2481, 56557, 1002, 208814, 16924, 1231, 17, 19,
34, 59283, 1152, 4, 77658, 915, 210, 1936, 106863,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 2566, 69408, 73736, 1400, 473, 2213, 267, 131388,
17817, 9781, 158974, 3262, 718, 35752, 2496, 1336, 20941,
530, 1701, 44920, 133198, 34, 2550, 44, 328, 61066,
1258, 8049, 7171, 5448, 77658, 915, 210, 16449, 5952,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 309, 4904, 1130,
38782, 1002, 1119, 29052, 1485, 5161, 4782, 427, 31451,
83342, 915, 11, 3804, 3171, 173064, 9955, 760, 5279,
10641, 7182, 4443, 2815, 77658, 915, 210, 16449, 5952,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 227985, 5484, 915, 2566, 137538, 78869, 12122, 2963,
3226, 15756, 1965, 3276, 14967, 6610, 664, 3509, 427,
112046, 1800, 21859, 3250, 77658, 915, 210, 1936, 106863,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 227985,
5484, 915, 2566, 18247, 11847, 53312, 1728, 461, 267,
53531, 473, 11229, 14456, 427, 2670, 25357, 82707, 14218,
1965, 60115, 2592, 11859, 77658, 915, 210, 1936, 106863,
3],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 84152, 7643, 2111,
473, 243647, 3276, 18100, 16916, 17, 38641, 1306, 1369,
105961, 4936, 28077, 17, 77658, 915, 210, 1936, 106863,
3]]),
'attention_mask':tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'labels':tensor([[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 16449, 5952,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 16449, 5952,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 16449, 5952,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3],
[ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3]])}
print(len(test_dataloader))
next(iter(test_dataloader))
425
{'input_ids':tensor([[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 74757, 64626, 12384, 44639, 613,
52282, 2670, 79920, 3344, 1002, 368, 17646, 14472, 8348,
664, 718, 4, 19036, 17, 31849, 17, 6312, 76,
44, 62470, 56, 91, 50, 14839, 21, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 227985, 5484, 915, 405, 187059,
2256, 664, 2550, 18833, 18607, 162467, 4, 1387, 6199,
3291, 23405, 613, 4657, 17082, 566, 3432, 368, 78851,
1185, 61273, 23181, 1553, 15596, 212, 116057, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 39762, 2566, 22253, 6201, 75701, 15, 632, 718,
5840, 10006, 6201, 18881, 427, 3804, 19528, 267, 158974,
1320, 368, 10029, 632, 49666, 92, 34, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 227985, 5484, 915, 2566, 104565, 8695, 2089, 6140,
109676, 99579, 1369, 512, 368, 4570, 54, 632, 368,
1503, 241485, 132226, 15, 982, 727, 1152, 18100, 861,
32596, 77597, 168154, 1306, 132226, 4346, 87843, 17, 130462,
364, 32923, 89, 53, 8309, 20, 75, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 227985, 5484, 915, 2566,
14173, 2960, 29906, 387, 20706, 49337, 1369, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 227985, 5484, 915, 2566, 219553, 45736,
36876, 1713, 72, 707, 187205, 13002, 177324, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 233938, 28518, 13716,
427, 28146, 1119, 17918, 17, 236706, 368, 214997, 7555,
48659, 5276, 21600, 343, 17, 51416, 22403, 318, 1531,
1306, 1130, 20934, 567, 101161, 184849, 87843, 17, 1594,
15231, 2052, 16642, 20, 7180, 80, 26, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 80, 2068, 479, 2566, 80,
1376, 878, 147587, 3904, 632, 368, 6084, 65673, 78851,
11736, 15527, 19082, 33151, 461, 17, 45575, 17887, 632,
5219, 14216, 68870, 5967, 1841, 4346, 87843, 17, 1594,
14512, 27, 71, 8184, 19, 290, 63748, 77658, 915,
210]]),
'attention_mask':tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
3.3 通过调用 get_peft_model 方法包装基础的 Transformer 模型¶
# creating model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
通过 print_trainable_parameters 方法可以查看到 P-Tuning v2 可训练参数的数量(仅为1,474,560)以及占比(仅为0.2629%)。
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
trainable params:51,461,120 || all params:610,675,712 || trainable%:8.426914479939231
PEFT 中 Prefix Tuning 相关的代码是基于清华开源的P-tuning-v2 进行的重构;同时,我们可以在chatglm-6b和chatglm2-6b中看到类似的代码。PEFT 中源码如下所示。
class PrefixEncoder(torch.nn.Module):
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
token_dim = config.token_dim
num_layers = config.num_layers
encoder_hidden_size = config.encoder_hidden_size
num_virtual_tokens = config.num_virtual_tokens
if self.prefix_projection and not config.inference_mode:
# Use a two-layer MLP to encode the prefix
# 初始化重参数化的编码器
self.embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
self.transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
else:
self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.transform(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
从上面的源码也可以看到 Prefix Tuning 与 P-Tuning v2 最主要的差别就是是否进行重新参数化编码。
model
PeftModelForCausalLM(
(base_model):BloomForCausalLM(
(transformer):BloomModel(
(word_embeddings):Embedding(250880, 1024)
(word_embeddings_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(h):ModuleList(
(0):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(1):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(2):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(3):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(4):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(5):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(6):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(7):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(8):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(9):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(10):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(11):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(12):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(13):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(14):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(15):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(16):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(17):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(18):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(19):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(20):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(21):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(22):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(23):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
(ln_f):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(lm_head):Linear(in_features=1024, out_features=250880, bias=False)
)
(prompt_encoder):ModuleDict(
(default):PrefixEncoder(
(embedding):Embedding(30, 1024)
(transform):Sequential(
(0):Linear(in_features=1024, out_features=1024, bias=True)
(1):Tanh()
(2):Linear(in_features=1024, out_features=49152, bias=True)
)
)
)
(word_embeddings):Embedding(250880, 1024)
)
model.peft_config
{'default':PrefixTuningConfig(peft_type=<PeftType.PREFIX_TUNING:'PREFIX_TUNING'>, auto_mapping=None, base_model_name_or_path='/data/nfs/llm/model/bloomz-560m', revision=None, task_type=<TaskType.CAUSAL_LM:'CAUSAL_LM'>, inference_mode=False, num_virtual_tokens=30, token_dim=1024, num_transformer_submodules=1, num_attention_heads=16, num_layers=24, encoder_hidden_size=1024, prefix_projection=True)}
3.4 模型训练¶
模型训练的其余部分均无需更改,当模型训练完成之后,保存高效微调部分的模型权重以供模型推理即可。
# model
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
# print(batch)
# print(batch["input_ids"].shape)
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}:{train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
100%|██████████| 7/7 [00:01<00:00, 4.72it/s] 100%|██████████| 7/7 [00:00<00:00, 22.29it/s]
epoch=0:train_ppl=tensor(1.2153e+26, device='cuda:0') train_epoch_loss=tensor(60.0622, device='cuda:0') eval_ppl=tensor(7.7051e+19, device='cuda:0') eval_epoch_loss=tensor(45.7910, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.37it/s] 100%|██████████| 7/7 [00:00<00:00, 22.24it/s]
epoch=1:train_ppl=tensor(1.4996e+18, device='cuda:0') train_epoch_loss=tensor(41.8517, device='cuda:0') eval_ppl=tensor(1.0033e+15, device='cuda:0') eval_epoch_loss=tensor(34.5421, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.74it/s] 100%|██████████| 7/7 [00:00<00:00, 22.10it/s]
epoch=2:train_ppl=tensor(5.3591e+13, device='cuda:0') train_epoch_loss=tensor(31.6124, device='cuda:0') eval_ppl=tensor(2.4683e+11, device='cuda:0') eval_epoch_loss=tensor(26.2320, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.77it/s] 100%|██████████| 7/7 [00:00<00:00, 21.87it/s]
epoch=3:train_ppl=tensor(1.7712e+10, device='cuda:0') train_epoch_loss=tensor(23.5975, device='cuda:0') eval_ppl=tensor(2.8744e+08, device='cuda:0') eval_epoch_loss=tensor(19.4765, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.75it/s] 100%|██████████| 7/7 [00:00<00:00, 22.04it/s]
epoch=4:train_ppl=tensor(25556452., device='cuda:0') train_epoch_loss=tensor(17.0564, device='cuda:0') eval_ppl=tensor(842123.9375, device='cuda:0') eval_epoch_loss=tensor(13.6437, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.74it/s] 100%|██████████| 7/7 [00:00<00:00, 22.07it/s]
epoch=5:train_ppl=tensor(157362.0938, device='cuda:0') train_epoch_loss=tensor(11.9663, device='cuda:0') eval_ppl=tensor(29300.7930, device='cuda:0') eval_epoch_loss=tensor(10.2854, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.74it/s] 100%|██████████| 7/7 [00:00<00:00, 22.06it/s]
epoch=6:train_ppl=tensor(9741.4102, device='cuda:0') train_epoch_loss=tensor(9.1841, device='cuda:0') eval_ppl=tensor(3307.9692, device='cuda:0') eval_epoch_loss=tensor(8.1041, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.47it/s] 100%|██████████| 7/7 [00:00<00:00, 22.15it/s]
epoch=7:train_ppl=tensor(2145.2480, device='cuda:0') train_epoch_loss=tensor(7.6710, device='cuda:0') eval_ppl=tensor(1604.1796, device='cuda:0') eval_epoch_loss=tensor(7.3804, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.71it/s] 100%|██████████| 7/7 [00:00<00:00, 22.13it/s]
epoch=8:train_ppl=tensor(1214.0173, device='cuda:0') train_epoch_loss=tensor(7.1017, device='cuda:0') eval_ppl=tensor(1103.5812, device='cuda:0') eval_epoch_loss=tensor(7.0063, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.76it/s] 100%|██████████| 7/7 [00:00<00:00, 21.82it/s]
epoch=9:train_ppl=tensor(1016.2148, device='cuda:0') train_epoch_loss=tensor(6.9238, device='cuda:0') eval_ppl=tensor(952.7982, device='cuda:0') eval_epoch_loss=tensor(6.8594, device='cuda:0')
# 模型评估
model.eval()
i = 16
inputs = tokenizer(f'{text_column} :{dataset["test"][i]["Tweet text"]} Label :', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
Hey @nytimes your link to cancel my subscription isn't working and nobody is answering the chat. Please don't play that kind of stupid game.
{'input_ids':tensor([[227985, 5484, 915, 54078, 2566, 7782, 24502, 2632, 8989,
427, 36992, 2670, 140711, 21994, 10789, 530, 88399, 632,
183542, 368, 44799, 17, 29901, 5926, 7229, 861, 11596,
461, 78851, 14775, 17, 77658, 915, 210]]), 'attention_mask':tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
tensor([[227985, 5484, 915, 54078, 2566, 7782, 24502, 2632, 8989,
427, 36992, 2670, 140711, 21994, 10789, 530, 88399, 632,
183542, 368, 44799, 17, 29901, 5926, 7229, 861, 11596,
461, 78851, 14775, 17, 77658, 915, 210, 1936, 106863,
1936, 106863, 1936, 106863, 1936, 106863, 1936, 106863]],
device='cuda:0')
["Tweet text :Hey @nytimes your link to cancel my subscription isn't working and nobody is answering the chat. Please don't play that kind of stupid game. Label :no complaintno complaintno complaintno complaintno complaint"]
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
输出的模型权重文件如下所示:
/data/nfs/llm/model/bloomz-560m_PREFIX_TUNING_CAUSAL_LM
├── [ 390] adapter_config.json
├── [5.6M] adapter_model.bin
└── [ 93] README.md
0 directories, 3 files
注意:这里只会保存经过训练的增量 PEFT 权重。其中,adapter_config.json 为 P-Tuning v2 / Prefix Tuning 配置文件;adapter_model.bin 为 P-Tuning v2 / Prefix Tuning 权重文件。
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
print("--------------")
!tree -h $peft_model_id
huggingface/tokenizers:The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) 5.7M /data/nfs/llm/model/bloomz-560m_PREFIX_TUNING_CAUSAL_LM/adapter_model.bin -------------- huggingface/tokenizers:The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) /data/nfs/llm/model/bloomz-560m_PREFIX_TUNING_CAUSAL_LM ├── [ 389] adapter_config.json ├── [5.6M] adapter_model.bin └── [ 111] README.md 0 directories, 3 files
3.5 加载微调后的权重文件进行推理¶
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
model.to(device)
model.eval()
i = 4
inputs = tokenizer(f'{text_column} :{dataset["test"][i]["Tweet text"]} Label :', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
@greateranglia Ok thanks...
{'input_ids':tensor([[227985, 5484, 915, 2566, 14173, 2960, 29906, 387, 20706,
49337, 1369, 77658, 915, 210]]), 'attention_mask':tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
tensor([[227985, 5484, 915, 2566, 14173, 2960, 29906, 387, 20706,
49337, 1369, 77658, 915, 210, 1936, 106863, 1936, 106863,
1936, 106863, 1936, 106863, 1936, 106863]], device='cuda:0')
['Tweet text :@greateranglia Ok thanks... Label :no complaintno complaintno complaintno complaintno complaint']