Prompt Tuning¶
1.Prompt Tuning 简述¶
Prompt Tuning(论文:The Power of Scale for Parameter-Efficient Prompt Tuning),该方法可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。
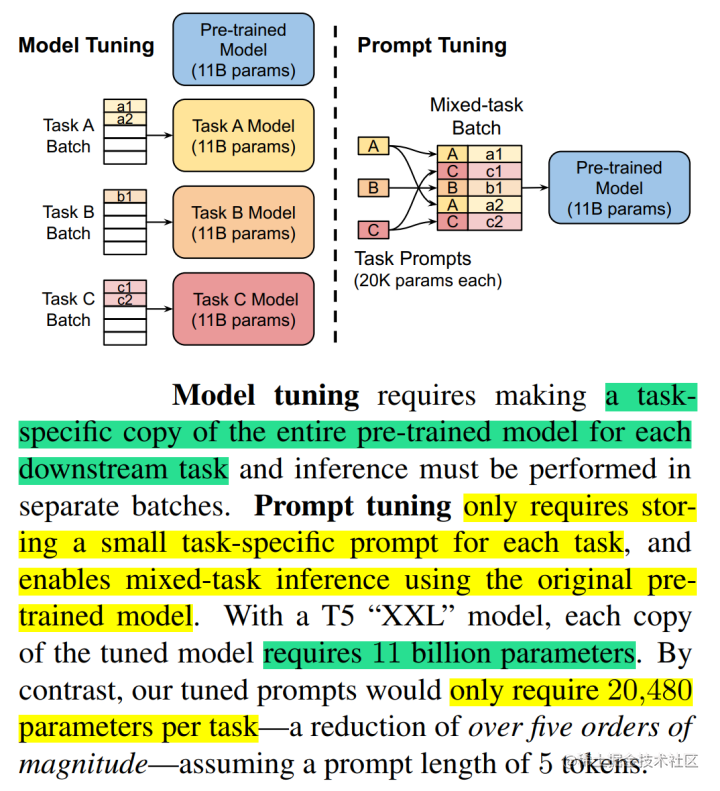
2.微调步骤¶
2.1 导入库¶
In [ ]:
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
/home/guodong.li/virtual-venv/peft-venv-py310-cu117/lib/python3.10/site-packages/tqdm/auto.py:21:TqdmWarning:IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
[2023-07-20 19:48:06,759] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)
2.2 Prompt Tuning 微调方法对应的配置¶
In [ ]:
device = "cuda"
model_name_or_path = "/data/nfs/llm/model/bloomz-560m"
tokenizer_name_or_path = "/data/nfs/llm/model/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
dataset_name = "twitter_complaints"
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 10
batch_size = 8
参数说明:
prompt_tuning_init:提示嵌入的初始化方法。PEFT支持文本(TEXT)和随机(RANDOM)初始化。在原理篇中提到过 Prompt token 的初始化方法和长度对于模型性能有影响。与随机初始化和使用样本词汇表初始化相比,Prompt Tuning 采用类标签初始化模型的效果更好。不过随着模型参数规模的提升,这种gap最终会消失。因此,如果需要使用类标签和样本词汇表初始化需指定为TEXT。prompt_tuning_init_text:用于初始化提示嵌入的文本,在使用文本(TEXT)初始化方法时使用。task_type:指定任务类型。如:条件生成任务(SEQ_2_SEQ_LM),因果语言建模(CAUSAL_LM)等。num_virtual_tokens:指定虚拟Token数。在原理篇中,提到过提示虚拟 Token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了);同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使提示虚拟 Token 长度很短,对性能也不会有太大的影响)。
In [ ]:
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
# dataset = load_dataset("/home/guodong.li/data/peft/raft/raft.py", dataset_name, cache_dir="/home/guodong.li/data/peft/data")
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
Found cached dataset raft (/home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84) 100%|██████████| 2/2 [00:00<00:00, 759.01it/s] Loading cached processed dataset at /home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84/cache-0e20fff6b1d898ca.arrow Loading cached processed dataset at /home/guodong.li/data/peft/data/raft/twitter_complaints/1.1.0/79c4de1312c1e3730043f7db07179c914f48403101f7124e2fe336f6f54d9f84/cache-8d14a62b8a688c19.arrow
['Unlabeled', 'complaint', 'no complaint']
DatasetDict({
train:Dataset({
features:['Tweet text', 'ID', 'Label', 'text_label'],
num_rows:50
})
test:Dataset({
features:['Tweet text', 'ID', 'Label', 'text_label'],
num_rows:3399
})
})
Out[ ]:
{'Tweet text':'@HMRCcustomers No this is my first job',
'ID':0,
'Label':2,
'text_label':'no complaint'}
In [ ]:
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print("target_max_length:", target_max_length)
# 预处理
def preprocess_function(examples):
batch_size = len(examples[text_column])
print("batch_size:", batch_size)
inputs = [f"{text_column} :{x} Label :" for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
if i == 0:
print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
#print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (max_length - len(sample_input_ids)) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs["attention_mask"][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
if i == 0:
print("model_inputs input_ids:", model_inputs["input_ids"][i])
print("model_inputs attention_mask:", model_inputs["attention_mask"][i])
print("labels input_ids:", labels["input_ids"][i])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
print("column_names:", dataset["train"].column_names)
# 将原始的训练和测试数据同时预处理,然后作为训练和评估数据集
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["train"]
# 训练与评估使用同一份数据,但是训练数据打乱
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
print(len(train_dataloader))
print(len(eval_dataloader))
target_max_length:3 column_names:['Tweet text', 'ID', 'Label', 'text_label']
batch_size:50
0 [227985, 5484, 915, 2566, 169403, 15296, 36272, 525, 3928, 1119, 632, 2670, 3968, 15270, 77658, 915, 210] [1936, 106863, 3]
model_inputs input_ids:tensor([ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 227985,
5484, 915, 2566, 169403, 15296, 36272, 525, 3928, 1119,
632, 2670, 3968, 15270, 77658, 915, 210, 1936, 106863,
3])
model_inputs attention_mask:tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
labels input_ids:tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 1936, 106863,
3])
Running tokenizer on dataset: 0%| | 0/3399 [00:00<?, ? examples/s]
batch_size:1000
Running tokenizer on dataset: 29%|██▉ | 1000/3399 [00:00<00:00, 9029.31 examples/s]
0 [227985, 5484, 915, 2566, 74757, 64626, 12384, 44639, 613, 52282, 2670, 79920, 3344, 1002, 368, 17646, 14472, 8348, 664, 718, 4, 19036, 17, 31849, 17, 6312, 76, 44, 62470, 56, 91, 50, 14839, 21, 77658, 915, 210] [3074, 4762, 60943, 3]
model_inputs input_ids:tensor([ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 227985, 5484, 915, 2566,
74757, 64626, 12384, 44639, 613, 52282, 2670, 79920, 3344,
1002, 368, 17646, 14472, 8348, 664, 718, 4, 19036,
17, 31849, 17, 6312, 76, 44, 62470, 56, 91,
50, 14839, 21, 77658, 915, 210, 3074, 4762, 60943,
3])
model_inputs attention_mask:tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
labels input_ids:tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
3074, 4762, 60943, 3])
batch_size:1000
0 [227985, 5484, 915, 232004, 2932, 1188, 221189, 195869, 13, 77658, 915, 210] [3074, 4762, 60943, 3]
model_inputs input_ids:tensor([ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 227985, 5484, 915, 232004, 2932, 1188,
221189, 195869, 13, 77658, 915, 210, 3074, 4762, 60943,
3])
model_inputs attention_mask:tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
labels input_ids:tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
3074, 4762, 60943, 3])
Running tokenizer on dataset: 59%|█████▉ | 2000/3399 [00:00<00:00, 9497.52 examples/s]
batch_size:1000
0 [227985, 5484, 915, 2566, 99198, 53312, 2566, 99198, 53312, 7064, 1074, 1800, 138435, 17, 77658, 915, 210] [3074, 4762, 60943, 3]
model_inputs input_ids:tensor([ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 2566, 99198, 53312, 2566, 99198, 53312, 7064, 1074,
1800, 138435, 17, 77658, 915, 210, 3074, 4762, 60943,
3])
model_inputs attention_mask:tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
labels input_ids:tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
3074, 4762, 60943, 3])
batch_size:399
0 [227985, 5484, 915, 2566, 669, 28503, 2633, 34712, 2144, 4867, 2670, 4676, 77658, 915, 210] [3074, 4762, 60943, 3]
model_inputs input_ids:tensor([ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 669, 28503, 2633, 34712, 2144,
4867, 2670, 4676, 77658, 915, 210, 3074, 4762, 60943,
3])
model_inputs attention_mask:tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
labels input_ids:tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
3074, 4762, 60943, 3])
7
7
In [ ]:
def test_preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} :{x} Label :" for x in examples[text_column]]
model_inputs = tokenizer(inputs)
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * ( max_length - len(sample_input_ids)) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs["attention_mask"][i]
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
return model_inputs
# 将原始的测试数据用于测试
test_dataset = dataset["test"].map(
test_preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
next(iter(test_dataloader))
Out[ ]:
{'input_ids':tensor([[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 74757, 64626, 12384, 44639, 613,
52282, 2670, 79920, 3344, 1002, 368, 17646, 14472, 8348,
664, 718, 4, 19036, 17, 31849, 17, 6312, 76,
44, 62470, 56, 91, 50, 14839, 21, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 227985, 5484, 915, 405, 187059,
2256, 664, 2550, 18833, 18607, 162467, 4, 1387, 6199,
3291, 23405, 613, 4657, 17082, 566, 3432, 368, 78851,
1185, 61273, 23181, 1553, 15596, 212, 116057, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 227985, 5484,
915, 39762, 2566, 22253, 6201, 75701, 15, 632, 718,
5840, 10006, 6201, 18881, 427, 3804, 19528, 267, 158974,
1320, 368, 10029, 632, 49666, 92, 34, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 227985, 5484, 915, 2566, 104565, 8695, 2089, 6140,
109676, 99579, 1369, 512, 368, 4570, 54, 632, 368,
1503, 241485, 132226, 15, 982, 727, 1152, 18100, 861,
32596, 77597, 168154, 1306, 132226, 4346, 87843, 17, 130462,
364, 32923, 89, 53, 8309, 20, 75, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 227985, 5484, 915, 2566,
14173, 2960, 29906, 387, 20706, 49337, 1369, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 227985, 5484, 915, 2566, 219553, 45736,
36876, 1713, 72, 707, 187205, 13002, 177324, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 227985, 5484, 915, 2566, 233938, 28518, 13716,
427, 28146, 1119, 17918, 17, 236706, 368, 214997, 7555,
48659, 5276, 21600, 343, 17, 51416, 22403, 318, 1531,
1306, 1130, 20934, 567, 101161, 184849, 87843, 17, 1594,
15231, 2052, 16642, 20, 7180, 80, 26, 77658, 915,
210],
[ 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3,
227985, 5484, 915, 2566, 80, 2068, 479, 2566, 80,
1376, 878, 147587, 3904, 632, 368, 6084, 65673, 78851,
11736, 15527, 19082, 33151, 461, 17, 45575, 17887, 632,
5219, 14216, 68870, 5967, 1841, 4346, 87843, 17, 1594,
14512, 27, 71, 8184, 19, 290, 63748, 77658, 915,
210]]),
'attention_mask':tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
2.3 通过调用 get_peft_model 方法包装基础的 Transformer 模型¶
In [ ]:
# creating model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
通过 print_trainable_parameters 方法可以查看可训练参数的数量(仅为8,192)以及占比(仅为0.00146%)。
In [ ]:
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
trainable params:8,192 || all params:559,222,784 || trainable%:0.0014648902430985358
Prompt Tuning 模型类结构如下所示:
In [ ]:
model
Out[ ]:
PeftModelForCausalLM(
(base_model):BloomForCausalLM(
(transformer):BloomModel(
(word_embeddings):Embedding(250880, 1024)
(word_embeddings_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(h):ModuleList(
(0):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(1):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(2):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(3):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(4):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(5):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(6):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(7):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(8):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(9):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(10):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(11):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(12):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(13):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(14):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(15):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(16):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(17):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(18):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(19):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(20):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(21):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(22):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
(23):BloomBlock(
(input_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(self_attention):BloomAttention(
(query_key_value):Linear(in_features=1024, out_features=3072, bias=True)
(dense):Linear(in_features=1024, out_features=1024, bias=True)
(attention_dropout):Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp):BloomMLP(
(dense_h_to_4h):Linear(in_features=1024, out_features=4096, bias=True)
(gelu_impl):BloomGelu()
(dense_4h_to_h):Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
(ln_f):LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(lm_head):Linear(in_features=1024, out_features=250880, bias=False)
)
(prompt_encoder):ModuleDict(
(default):PromptEmbedding(
(embedding):Embedding(8, 1024)
)
)
(word_embeddings):Embedding(250880, 1024)
)
从模型类结构可以看到,Prompt Tuning 只在输入层加入 prompt virtual tokens,其他地方均没有变化,具体可查看 PromptEmbedding 的源码。
class PromptEmbedding(torch.nn.Module):
def __init__(self, config, word_embeddings):
super().__init__()
total_virtual_tokens = config.num_virtual_tokens * config.num_transformer_submodules
# 初始化 embedding 层
self.embedding = torch.nn.Embedding(total_virtual_tokens, config.token_dim)
# 如果使用文本进行初始化,执行如下逻辑,PromptTuningConfig 配置类需要传入初始化文本。
if config.prompt_tuning_init == PromptTuningInit.TEXT:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name_or_path)
init_text = config.prompt_tuning_init_text
init_token_ids = tokenizer(init_text)["input_ids"]
# Trim or iterate until num_text_tokens matches total_virtual_tokens
num_text_tokens = len(init_token_ids)
if num_text_tokens > total_virtual_tokens:
init_token_ids = init_token_ids[:total_virtual_tokens]
elif num_text_tokens < total_virtual_tokens:
num_reps = math.ceil(total_virtual_tokens / num_text_tokens)
init_token_ids = init_token_ids * num_reps
init_token_ids = init_token_ids[:total_virtual_tokens]
word_embedding_weights = word_embeddings(torch.LongTensor(init_token_ids)).detach().clone()
word_embedding_weights = word_embedding_weights.to(torch.float32)
# 初始化embedding层的权重
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings
2.4 模型训练¶
模型训练的其余部分均无需更改,当模型训练完成之后,保存高效微调部分的模型权重以供模型推理即可。
In [ ]:
# model
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
In [ ]:
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
# print(batch)
# print(batch["input_ids"].shape)
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}:{train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
100%|██████████| 7/7 [00:01<00:00, 4.92it/s] 100%|██████████| 7/7 [00:00<00:00, 21.74it/s]
epoch=0:train_ppl=tensor(2.8311e+13, device='cuda:0') train_epoch_loss=tensor(30.9743, device='cuda:0') eval_ppl=tensor(91053.0859, device='cuda:0') eval_epoch_loss=tensor(11.4192, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.91it/s] 100%|██████████| 7/7 [00:00<00:00, 21.64it/s]
epoch=1:train_ppl=tensor(13540.4053, device='cuda:0') train_epoch_loss=tensor(9.5134, device='cuda:0') eval_ppl=tensor(2038.3656, device='cuda:0') eval_epoch_loss=tensor(7.6199, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.93it/s] 100%|██████████| 7/7 [00:00<00:00, 21.66it/s]
epoch=2:train_ppl=tensor(911.4009, device='cuda:0') train_epoch_loss=tensor(6.8150, device='cuda:0') eval_ppl=tensor(407.7935, device='cuda:0') eval_epoch_loss=tensor(6.0108, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.96it/s] 100%|██████████| 7/7 [00:00<00:00, 21.66it/s]
epoch=3:train_ppl=tensor(362.4507, device='cuda:0') train_epoch_loss=tensor(5.8929, device='cuda:0') eval_ppl=tensor(344.7443, device='cuda:0') eval_epoch_loss=tensor(5.8428, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 11.04it/s] 100%|██████████| 7/7 [00:00<00:00, 21.48it/s]
epoch=4:train_ppl=tensor(280.6489, device='cuda:0') train_epoch_loss=tensor(5.6371, device='cuda:0') eval_ppl=tensor(227.5656, device='cuda:0') eval_epoch_loss=tensor(5.4274, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.96it/s] 100%|██████████| 7/7 [00:00<00:00, 21.56it/s]
epoch=5:train_ppl=tensor(210.2800, device='cuda:0') train_epoch_loss=tensor(5.3484, device='cuda:0') eval_ppl=tensor(201.9129, device='cuda:0') eval_epoch_loss=tensor(5.3078, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.95it/s] 100%|██████████| 7/7 [00:00<00:00, 21.50it/s]
epoch=6:train_ppl=tensor(189.7844, device='cuda:0') train_epoch_loss=tensor(5.2459, device='cuda:0') eval_ppl=tensor(177.7323, device='cuda:0') eval_epoch_loss=tensor(5.1803, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 11.05it/s] 100%|██████████| 7/7 [00:00<00:00, 21.56it/s]
epoch=7:train_ppl=tensor(168.3532, device='cuda:0') train_epoch_loss=tensor(5.1261, device='cuda:0') eval_ppl=tensor(162.9865, device='cuda:0') eval_epoch_loss=tensor(5.0937, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 11.00it/s] 100%|██████████| 7/7 [00:00<00:00, 21.45it/s]
epoch=8:train_ppl=tensor(158.9806, device='cuda:0') train_epoch_loss=tensor(5.0688, device='cuda:0') eval_ppl=tensor(154.2098, device='cuda:0') eval_epoch_loss=tensor(5.0383, device='cuda:0')
100%|██████████| 7/7 [00:00<00:00, 10.75it/s] 100%|██████████| 7/7 [00:00<00:00, 21.42it/s]
epoch=9:train_ppl=tensor(150.1807, device='cuda:0') train_epoch_loss=tensor(5.0118, device='cuda:0') eval_ppl=tensor(151.4834, device='cuda:0') eval_epoch_loss=tensor(5.0205, device='cuda:0')
In [ ]:
# 模型评估
model.eval()
i = 33
inputs = tokenizer(f'{text_column} :{dataset["test"][i]["Tweet text"]} Label :', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
@TommyHilfiger Dramatic shopping exp. ordered 6 jeans same size (30/32) 2 fits / 2 too large / 2 too slim :same brand > different sizing
{'input_ids':tensor([[227985, 5484, 915, 2566, 226154, 126015, 5385, 259, 239364,
3396, 70823, 5853, 17, 57247, 1231, 191040, 5025, 7869,
375, 2324, 149349, 12, 415, 122321, 897, 415, 10136,
10021, 897, 415, 10136, 6497, 381, 915, 5025, 51950,
66869, 5955, 272, 20311, 77658, 915, 210]]), 'attention_mask':tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
tensor([[227985, 5484, 915, 2566, 226154, 126015, 5385, 259, 239364,
3396, 70823, 5853, 17, 57247, 1231, 191040, 5025, 7869,
375, 2324, 149349, 12, 415, 122321, 897, 415, 10136,
10021, 897, 415, 10136, 6497, 381, 915, 5025, 51950,
66869, 5955, 272, 20311, 77658, 915, 210, 1936, 106863,
2, 31, 4, 115574, 150936, 189, 31, 4]],
device='cuda:0')
['Tweet text :@TommyHilfiger Dramatic shopping exp. ordered 6 jeans same size (30/32) 2 fits / 2 too large / 2 too slim :same brand > different sizing Label :no complaint<!DOCTYPE html>\n<!']
In [ ]:
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
输出的模型权重文件如下所示:
/data/model/bloomz-560m_PROMPT_TUNING_CAUSAL_LM
├── [ 500] adapter_config.json
├── [ 33K] adapter_model.bin
└── [ 111] README.md
0 directories, 3 files
In [ ]:
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
print("--------------")
!tree -h $peft_model_id
huggingface/tokenizers:The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) 36K /data/nfs/llm/model/bloomz-560m_PROMPT_TUNING_CAUSAL_LM/adapter_model.bin -------------- huggingface/tokenizers:The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) /data/nfs/llm/model/bloomz-560m_PROMPT_TUNING_CAUSAL_LM ├── [ 500] adapter_config.json ├── [ 33K] adapter_model.bin └── [ 129] README.md 0 directories, 3 files
2.5 加载微调后的权重文件进行推理¶
In [ ]:
# 基于高效微调好的模型进行预训练。
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
print("model path:", config.base_model_name_or_path)
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
# 加载LoRA模型
model = PeftModel.from_pretrained(model, peft_model_id)
model path:/data/nfs/llm/model/bloomz-560m
In [ ]:
model.to(device)
model.eval()
i = 4
inputs = tokenizer(f'{text_column} :{dataset["test"][i]["Tweet text"]} Label :', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
@greateranglia Ok thanks...
{'input_ids':tensor([[227985, 5484, 915, 2566, 14173, 2960, 29906, 387, 20706,
49337, 1369, 77658, 915, 210]]), 'attention_mask':tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
tensor([[227985, 5484, 915, 2566, 14173, 2960, 29906, 387, 20706,
49337, 1369, 77658, 915, 210, 1936, 106863, 2, 31,
4, 115574, 150936, 189, 31, 55683]], device='cuda:0')
['Tweet text :@greateranglia Ok thanks... Label :no complaint<!DOCTYPE html>\n<html>']
In [ ]: